正文
今天要記錄的是累計彙總(Cumulative aggregates):
dplyr::cumall(): cumulative all() 搭配filter()提取資料到第一筆不符合的資料
dply::cumany(): cumulative any() 搭配filter()提取資料第一筆符合資料後的所有資料
dplyr::cummean(): cumulative mean() 累計平均值
範例:
library("dplyr")
x <- c(1, 3, 5, 2, 2)
x小於5後皆為FALSE
cumall(x < 5)

x等於3後皆為TRUE
cumany(x == 3)

cummax(): cumulative max() 累計最大值
cummin(): cumulative min() 累計最小值
cumsum(): cumulative sum() 累計總和
x <- 1:10
y <- 10:1
#1到10的累計總和
cumsum(x)
#10到1的累計總和,利用order_by()進行排序(在此為y)
order_by(y, cumsum(x))

今天使用"Sean Lahman Baseball Database"資料集產生範例資料集
library(Lahman)
batting <- Lahman::Batting %>%
as_tibble() %>%
select(playerID, yearID, teamID, G, AB:H) %>%
arrange(playerID, yearID, teamID) %>%
semi_join(Lahman::AwardsPlayers, by = "playerID")
players <- batting %>% group_by(playerID)
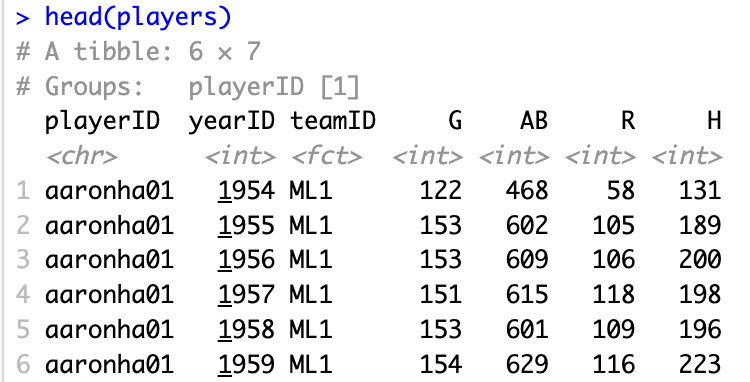
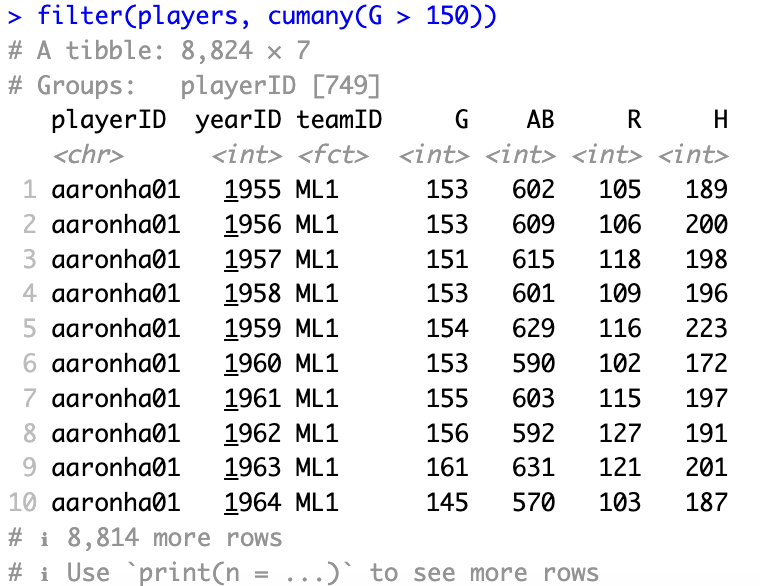
取得G大於150後的所有資料
filter(players, cumany(G > 150))
今天的小筆記就先到這邊,大家明天見~~
參考資料:

